I’ve been involved in dozens of performance testing projects over the years, and one thing has become crystal clear: most performance-related failures in production aren’t caused by a lack of tools or technology. They usually stem from common, avoidable mistakes that teams keep repeating.
In 2026, where users expect sub-second responses even during traffic spikes, and where slow performance directly impacts SEO rankings, conversion rates, and revenue, these mistakes can prove very costly. I’ve seen beautiful applications fail spectacularly under real load simply because the team overlooked some fundamental aspects of performance testing.
In this detailed guide, I’ll walk you through the most frequent performance testing mistakes I’ve observed (and sometimes made myself) and, more importantly, how to avoid them. These insights come from real projects and the work we do at SDET Tech helping companies build robust performance practices.
Mistake 1: Treating Performance Testing as a One-Time Activity
One of the biggest mistakes is running performance tests only before major releases. Teams often treat it as a checkbox instead of an ongoing practice.
Why it’s dangerous: Modern applications change frequently with continuous deployments. What performs well today can degrade tomorrow due to new features, third-party updates, or growing data volumes.
How to avoid it: Make performance testing continuous. Integrate lightweight checks into your CI/CD pipeline and run comprehensive tests regularly. Adopt a shift-left approach where developers test components early. At SDET Tech, we recommend scheduling baseline tests every sprint and full load tests before every major release. This habit alone prevents many nasty surprises.
Mistake 2: Using Unrealistic Test Data and Scenarios
Many teams use synthetic or randomly generated data that doesn’t reflect real production usage. They test simple happy paths while ignoring complex user journeys.
Why it’s dangerous: Real users behave differently. They use multiple tabs, slow networks, older devices, and perform actions in unpredictable sequences. Unrealistic tests create a false sense of security.
How to avoid it: Base your test scenarios on actual production analytics, logs, and user behavior data. Include realistic think times, varied user personas, geographic distribution, and edge cases. Always test complete user journeys like login → search → checkout → payment. This makes your performance testing far more valuable.
Mistake 3: Testing in Non-Production-Like Environments
Testing on a small staging server with minimal data while production runs on auto-scaling cloud infrastructure is a classic error.
Why it’s dangerous: Behavior under load differs dramatically between environments. You’ll miss issues related to network latency, database scaling, CDN configuration, or container orchestration.
How to avoid it: Invest time in making test environments as close to production as possible. Use infrastructure-as-code to spin up temporary environments that mirror production. Leverage cloud testing platforms that can replicate real conditions. This small investment pays off hugely during actual load.
Mistake 4: Focusing Only on Backend While Ignoring Frontend Performance
Teams often spend all their effort on API and server testing but forget that users experience the frontend first.
Why it’s dangerous: In 2026, poor Core Web Vitals (LCP, INP, CLS) directly hurt SEO and user experience. Heavy JavaScript bundles, unoptimized images, and render-blocking resources can kill perceived performance even if the backend is fast.
How to avoid it: Include dedicated frontend performance testing using tools like Lighthouse, WebPageTest, and real-device testing. Measure and set budgets for Core Web Vitals. Optimize images, implement lazy loading, code splitting, and efficient caching strategies. A balanced approach covering both frontend and backend delivers the best results.
Mistake 5: Relying Solely on Automated Tools Without Human Analysis
Automated tools are great, but many teams stop at the reports without proper analysis.
Why it’s dangerous: Tools show symptoms but rarely explain the root cause. You might see high response times but miss that it’s caused by an N+1 database query or inefficient caching.
How to avoid it: Use automation for execution but always follow up with deep manual analysis. Correlate metrics across layers (frontend, backend, database, infrastructure). Use distributed tracing and observability tools. At SDET Tech, our experts combine powerful tools with human expertise to provide actionable insights rather than just raw data.
Mistake 6: Setting Wrong or Missing Performance Thresholds
Some teams don’t define clear performance budgets, while others set unrealistic ones that are either too strict or too lenient.
Why it’s dangerous: Without proper thresholds, you can’t objectively decide whether a test passed or failed. This leads to inconsistent decisions and overlooked regressions.
How to avoid it: Define clear, business-aligned performance SLAs and budgets early. Use percentile metrics (P95, P99) instead of just averages. Review and adjust these thresholds regularly as your application and user base grow. Make them part of your Definition of Done.
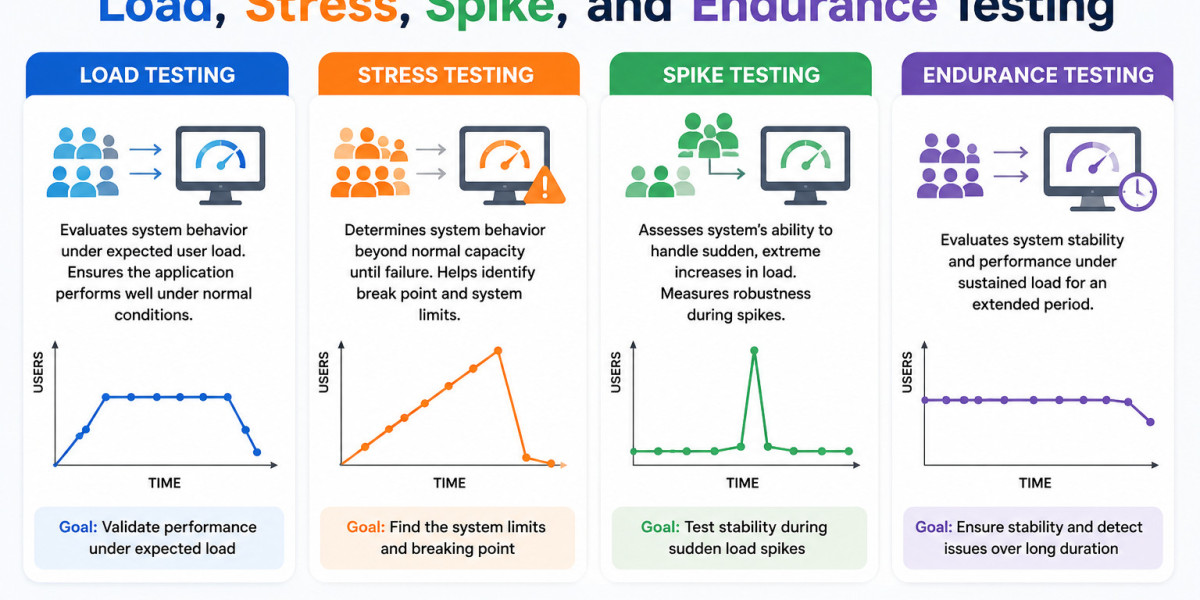
Mistake 7: Ignoring Long-Running Endurance and Soak Tests
Many teams focus heavily on load and stress testing but skip endurance tests.
Why it’s dangerous: Some issues like memory leaks, connection pool exhaustion, or gradual database slowdowns only appear after hours of continuous usage.
How to avoid it: Regularly run soak tests for 8–72 hours under realistic load. Monitor resource utilization trends over time. This practice has helped several SDET Tech clients catch subtle issues that would have caused outages in production.
Mistake 8: Poor Test Script Maintenance and Reusability
Teams often write one-off scripts that become outdated quickly and are difficult to maintain.
Why it’s dangerous: As the application evolves, outdated scripts give wrong results or break entirely, wasting time and reducing trust in the testing process.
How to avoid it: Write modular, reusable, and well-documented test scripts. Use version control and treat them like production code. Regularly review and update scripts when new features are added. Good scripting practices make performance testing sustainable in the long run.
Mistake 9: Not Involving Developers Early Enough
Performance testing is often left entirely to the QA team, with developers getting involved only when issues are found late.
Why it’s dangerous: Fixing performance issues late in the cycle is expensive and time-consuming. Many problems could have been prevented with better code design.
How to avoid it: Build a performance culture where developers take ownership. Provide basic training on writing performant code, set performance budgets at the component level, and include developers in test reviews. Shift-left is not just a buzzword — it’s a game changer.
Mistake 10: Failing to Monitor and Learn from Production
The ultimate mistake is treating pre-production testing as sufficient and ignoring real user data.
Why it’s dangerous: Even the best test strategies can’t catch every possible scenario in production.
How to avoid it: Implement strong observability with Real User Monitoring (RUM) and synthetic monitoring. Use feature flags for gradual rollouts. Conduct blameless post-mortems after any performance incidents and feed those learnings back into your testing strategy.
Real-World Example from Our Work at SDET Tech
We worked with a mid-sized e-commerce platform that was struggling with frequent slowdowns during sales events. After reviewing their process, we found they were committing almost all the mistakes mentioned above — unrealistic data, poor environment parity, no endurance testing, and minimal frontend checks.
After implementing a balanced strategy — realistic scenarios, proper CI/CD integration, frontend + backend testing, and continuous monitoring — their peak traffic handling improved dramatically. Average response time dropped by 68%, and cart abandonment during sales events reduced significantly.
Building a Strong Performance Testing Practice
Avoiding these mistakes requires a mindset shift. Treat performance testing as a continuous engineering practice rather than a phase in the project timeline. Combine the right tools, realistic scenarios, cross-team collaboration, and regular learning.
Start small if you’re overwhelmed. Pick the top 3–4 mistakes that are most relevant to your current situation and fix them first. Consistency beats perfection every time.
Final Thoughts
In 2026, performance is a key differentiator. Users are quick to abandon slow applications, and search engines reward fast experiences. By being aware of these common performance testing mistakes and proactively avoiding them, you can deliver applications that are not just functional but truly exceptional in terms of speed and reliability.
The teams that succeed are those that learn from past failures and build robust, sustainable performance practices.
Have you encountered any of these mistakes in your projects? Which one hurt you the most, and how did you overcome it? Share your stories in the comments — I read every one and often pick up new insights from the community.
If your team is struggling with performance issues or wants to build a mature performance testing practice from the ground up, feel free to reach out to SDET Tech. We specialize in identifying hidden bottlenecks, implementing practical strategies, and delivering measurable improvements for modern web and cloud-native applications.
Let’s stop repeating the same mistakes and start building faster, more resilient digital experiences together.









